Research without Re-search: Maximal Update Parametrization Yields Accurate Loss Prediction across Scales
 Mu-Scaling
Mu-Scaling
摘要
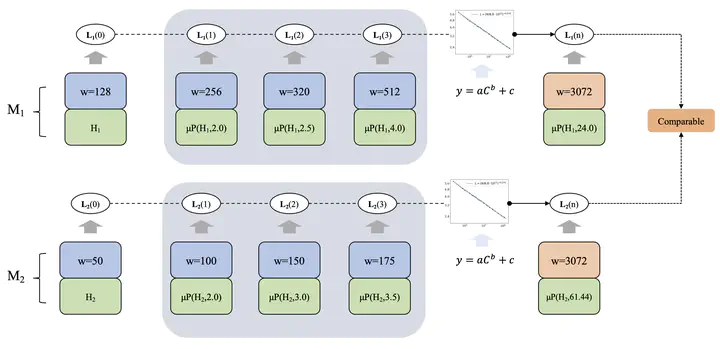
As language models scale up, it becomes increasingly expensive to verify research ideas because conclusions on small models do not trivially transfer to large ones. A possible solution is to establish a generic system that directly predicts some metrics for large models solely based on the results and hyperparameters from small models. Existing methods based on scaling laws require hyperparameter search on the largest models, which is impractical with limited resources. We address this issue by presenting our discoveries indicating that Maximal Update parametrization (uP) enables accurate fitting of scaling laws for hyperparameters close to common loss basins, without any search. Thus, different models can be directly compared on large scales with loss prediction even before the training starts. We propose a new paradigm as a first step towards reliable academic research for any model scale without heavy computation.